
IDC预测,到2022年,中国的人工智能市场投资规模将超过百亿美元,未来五年的复合增长率超过59%。
6月20日,第四范式在京举办了为期一天的产品发布会。第四范式CEO戴文渊、首席架构师胡时伟、首席研究科学家陈雨强、来自英特尔、百胜中国、工商银行、瑞金医院等产业和行业合作伙伴轮番登台展现第四范式未来发展目标和产业蓝图。
会上,第四范式还发布了企业AI转型的“1+N”战略方法、企业级AI软硬一体集成系统——SageOne、AutoML 2.0技术以及“启航”合作伙伴计划。
不过,最令i黑马&黑智感兴趣的还是企业AI转型的“1+N”战略方法。“1”是结合公司核心业务,把1个或几个对业务影响最大的场景做到极致;“N”是用最高的效率规模化落地尽可能多的应用场景,使场景的总体价值最大化。
这是人工智能公司与实体产业结合的一个重要的命题。下附戴文渊对企业智能化转型的“1+N”模式的思考。经编辑。
回到企业本身,无论是否使用AI技术,首先我们需要关心的企业需要提升什么业务价值。
首先,每个企业可能都会有1个或多个核心业务,这些业务提升会带动整个企业的提升。例如,最近几年,互联网应用越来越关心的“千人千面”,本质上是通过个性化服务应用提升客户活跃度,降低客户流失率。客户活跃度的提升,会带动企业整体的提升。对于零售或制造业企业,提升供应链效率,降低成本,也会带动企业核心竞争力的提升。面对这些核心应用场景,我们需要AI做到“极致的效果”,因为每提升一个百分点的效果,对企业都至关重要。
其次,很多企业也往往面临场景应用极其分散的情况。例如,大型金融企业,他们的业务往往较为分散。这种情况下,AI的规模化落地,往往比单场景的极致效果对企业更为重要。假设一个企业有一千个场景,其中一个场景提升10倍,对整个企业来说,只有百分之一的提升。而如果我们能高效地完成一千个场景的全面覆盖,即使每个场景只提升1倍,那也百分之百的提升。所以,面对场景众多的企业,AI的规模化落地能力是企业智能化转型的关键。
我们习惯把企业的核心场景称之为“1”,把众多的场景称之为“N”。通常企业的智能化转型,需要一个“1+N”应用模式。这里需要指出的是,“1”不一定只有一个应用,有些企业可能会有若干个“1”这样的核心应用,但一定不会很多。
企业的业务一定是和企业的发展目标相关的。例如,我们服务某知名国际零售集团,根据企业的发展目标,将其业务分为“开源”和“节流”两大类。
“开源”的目标主要和客户相关,包括提升客户留存率、单客户价值、平均客户留存时间等。手段上来说,可能有千人千面的推荐、coupon的营销等。AI在里面可以通过优化推荐、营销等环节,提升留存率、单客户价值等核心指标。
“节流”的目标主要是降低中后台运营的成本和提升运营效率。通过提升供应链等环节的效率,降低成本,提升企业的竞争力。这其中,个性化服务、供应链是核心应用,是“1”,1个百分点的提升就足以改变企业的竞争格局。而众多细分场景,如各种单据的OCR、各种场景的语音识别、智能客服、流程机器人等,是“N”,规模化的落地可以提升企业的整体效率。
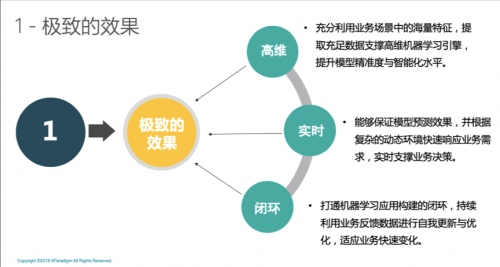
“1”一定要做到极致的效果,这类标杆型应用对于AI系统的要求较高。
一是高维,也就是精细,越高维度的AI,其效果上能做到越精细。过去的专家模型,往往维度(规则数量)在几个到几千个不等。传统意义上的高维模型,往往局限在万级别的维度遗下。第四范式开发的高维机器学习引擎,最高可支持到万亿(10^12)维度,通过极致的机器算力,实现远超传统几个数量级的精准性。
二是实时,随着服务线上化以及对极致体验的要求,对业务的实时响应要求越来越高。尤其面对高维,我们发现往往过去能做到实时的系统,做不到高维;能做到高维的系统,做不到实时。为此,第四范式自主研发了RTiDB系统,实现万亿维度模型毫秒级响应的精准决策。
三是闭环(自学习能力),任何系统都不可能完美,都可能会犯错。我们更怕的不是AI犯错误,而是AI持续不断地犯同样的错误。因此,持续利用业务应用过程中的反馈数据进行系统自我更新与优化的能力,是未来AI系统极其重要的核心能力。我们也经常发现,AI系统的最大提升,很多时候并不来自于系统上线的那一刻,而是来自于上线以后经年累月的自我迭代提升。
“N”追求的是规模化落地,现在我们服务的很多企业都面临着“全面AI改造”,在面对1千个甚至1万个场景时,如果每个都做到极致,代价和效率是不够的。实现规模化落地和极致效果的路径不完全一样。
首先需要建立一个统一的方法论,让更多人用统一方法规模化生产AI。第四范式建立了一个以 “库伯学习圈”理论为基础的AI方法论,并基于此构建了“先知”平台,将AI开发过程分成 “行为数据采集、反馈数据采集、模型训练、模型应用”四个标准步骤,我们帮助客户和合作伙伴的开发者在先知上按照这样的一二三四去产生AI。以我们服务的某大型央企为例,其开发者数量众多,AI开发者却非常有限,我们为其提供了统一的方法论和平台,让开发者针对业务目标,在上面开发各种各样的AI应用。
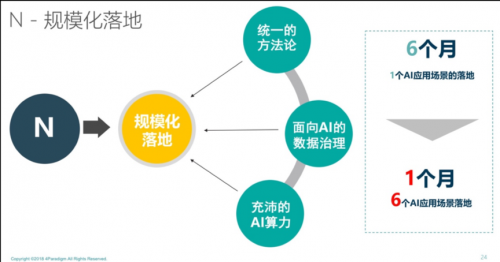
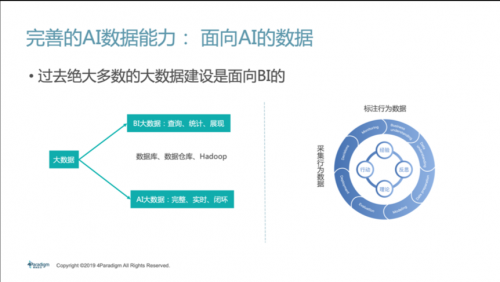
其次,AI规模化应用过程中要有完善的数据治理能力,尤其是对于大中型的企业,数据治理非常重要。可能我们过去已经做了大数据系统,但往往是面向BI建设的,BI大数据主要是帮助人去总结一些经验,因此更强调查询、统计、可视化等功能。AI大数据是给机器看的数据,需要的是完整、实时和支持机器自学习的闭环。两个大数据系统的设计理念天然不同,我们经常会看到企业由于过去建设了面向BI的大数据系统,又将AI建设在这个系统之上,非但没有帮到AI,反倒成为AI落地的障碍。因此,大规模AI实践过程中企业需要一套面向AI的数据治理系统,能够存取PB级甚至更大量的日志、支持实时存储、形成一个线上数据采集和处理的闭环等。
最后是AI算力,以往大家关注的焦点主要集中在两个方面:
一是通过购买大量的服务器和GPU来提升算力;二是通过芯片实现AI的加速。但是算力是一个完整的体系架构,甚至不仅仅包括硬件,而是软件和硬件的“结合体”,只有了解AI算法的运算架构与逻辑,才能针对硬件去做深层次的优化。AI系统其实是有“套路”的设计,具备固定的计算模式,它需要的是一个专用计算,不像大数据和软件需要的是通用计算。基于专用计算的特点,算法和软件其实可以直接定义好计算,提前把计算的部分去硬件化。
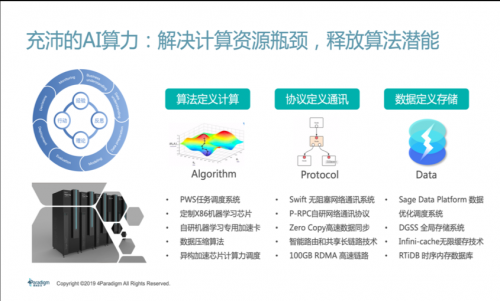
此外,过去传统的通用通信协议、存储系统也同样面临着无法支撑AI的困境,需要针对于AI算法的特性进行深度优化。以TCP的通信协议为例,该协议通过“三次握手”建立可靠的数据交换机制,保证数据传输不丢失。但AI只需要在传输过程中,保证数据的统计特性即可,传输100份数据与传输90份数据的统计结果差异微乎其微。第四范式从去年开始研究开发新的硬件体系SageOne,我们不是为了去生产硬件,而是为了设计软硬一体的方案,产出更适合人工智能专用算法的算力架构。
下附SageOne介绍:
第四范式本次发布的企业级 AI 软硬一体集成系统——SageOne,摒弃了传统算力堆砌硬件的方式,而采用由软件定义的专用AI系统架构,更好的理解AI 算法的运算架构与逻辑,更深层次软硬件一体化的优化和加速,全面满足企业AI应用的算力需求。
SageOne内置第四范式领先的自研AI训练引擎、AI推理引擎和AI特征存储引擎三大核心引擎, 通过业界领先的“软件定义计算”软硬一体技术构建了闭环企业AI系统,贯通硬件基础设施、AI核心引擎、AI平台和AI业务应用的全价值链条,全面支撑企业AI"1+N "业务场景应用需求。
以第四范式高维算法为基础,SageOne搭载第四范自主研发的硬件加速卡——4Paradigm ATX800,内置模型训练和特征工程等多种加速能力,支持自动优化训练超参数、高位特征计算过程I/O加速和高维GBDT训练加速等应用,在企业应用场景中表现出高达10倍的训练性能。
SageOne内置第四范式自主研发的高维、分布式网络通讯协议Swift,集成pPRC自研网络通信框架、零拷贝数据交换协议等AI领先通讯技术,结合基于CLX-AP架构的参数服务器集群,展现出业界顶级机器学习性能表现。SageOne在高维特征计算过程I/O最大10X加速,高维稀疏场景模型训练比GPU提速5X以上,自研pRPC通信框架比百度bRPC和谷歌gRPC提速3-10X。
内置行业领先的自研实时特征计算引擎和模型预估引擎,SageOne为企业AI应用提供特征处理过程免开发上线、线下线上一致性保证、一键生成预估服务、异构模型统一服务等AI核心应用服务,结合非易失性存储的无限缓存和超低延迟内存存储等硬件技术,确保企业AI应用时具备海量量时序特征计算和万亿维模型实时推理能力的同时,提供百万级并发实时请求支持和99.9%请求毫秒级响应的高并发业务极速响应服务。
此外,第四范式和英特尔联合实验室一直探索最佳优化技术,并针对最新Cascade Lake-AP处理器的全新AVX512指令集、多核心及主频利用率和CLX AP微架构IO总线的利用率进行全面优化。







