12月5日,火山引擎正式发布豆包语音识别模型 2.0(Doubao-Seed-ASR-2.0)。模型推理能力提升,通过深度理解上下文完成精准识别,上下文整体关键词召回率提升 20%;支持多模态视觉识别,不仅“听懂字”还能“看懂图”,通过单图和多图等视觉信息输入让文字识别更精准;支持日语、韩语、德语、法语等 13 种海外语种的精准识别。
豆包语音识别模型依托 Seed 混合专家大语言模型架构构建,在延续 1.0 版本中 20 亿参数高性能音频编码器优势的基础上,重点针对专有名词、人名、地名、品牌名称及易混淆多音字等复杂场景进行优化升级。而更强的上下文推理能力,让模型实现多模态信息理解、混合语言精准识别能力。
推理能力提升:从“目标词汇”到“深度推理”
豆包语音识别模型 2.0 基于 PPO 方案进行强化学习,不需要依赖目标词汇的历史出现记录,通过深度理解更加泛化的上下文即可完成精准识别,让语音识别更适配动态变化的真实交互场景,输出结果更准确。
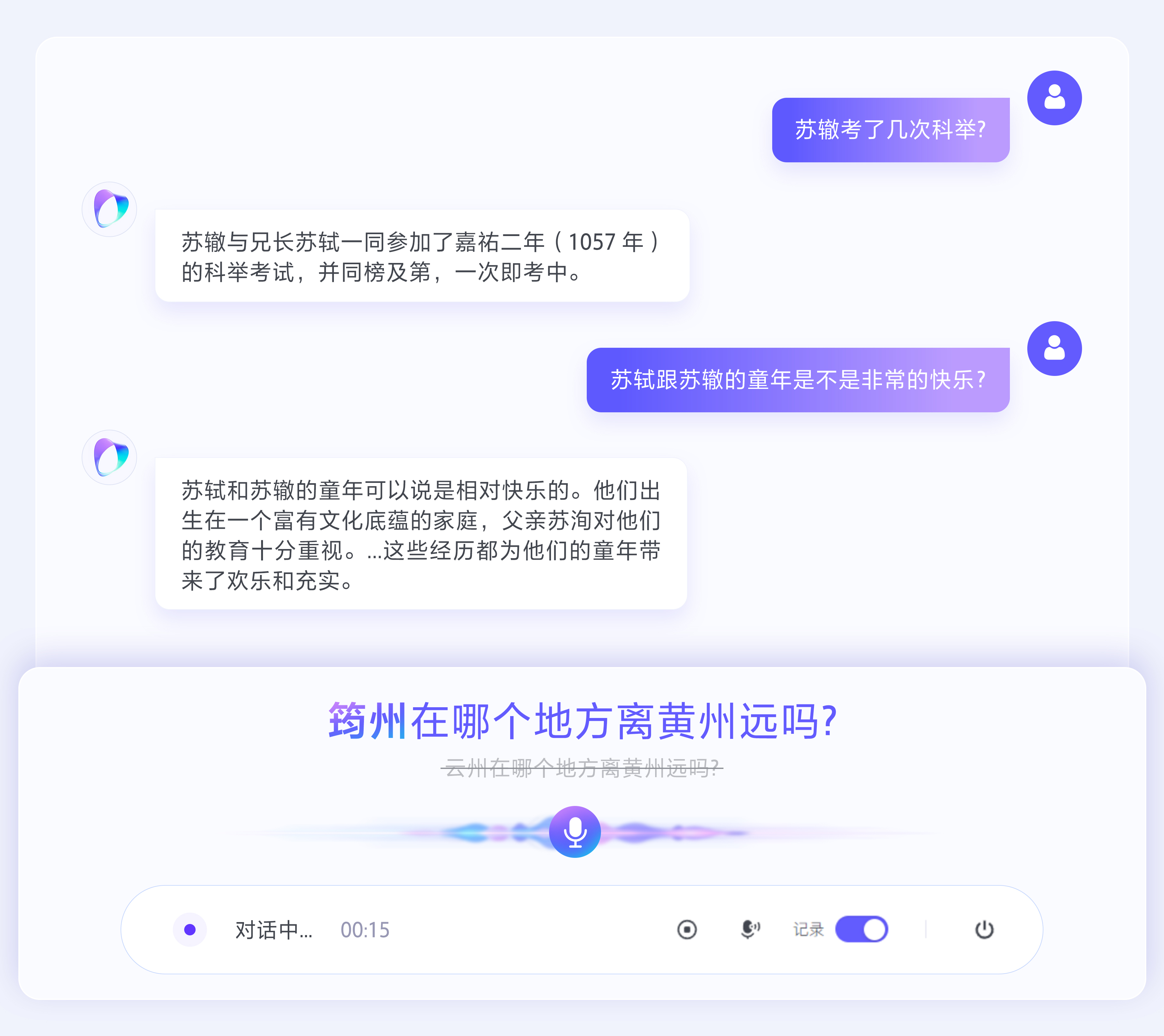
以历史人物生平讨论场景为例,当用户提及苏辙贬谪地 “筠州” 时,如果模型缺乏推理能力会易将其误识别为同音的 “云州”“郓州”等。而豆包语音识别模型 2.0 可依托 “当前讨论苏轼、苏辙” 这一背景,即便上下文从没出现过 “筠州”,也能通过逻辑推理锁定用户所指的特定地名,最终实现对多音字地名的精准识别。
模态理解进阶:从“听懂字”到“看懂景”
依托强大推理能力,豆包语音识别模型 2.0 将上下文理解范围从纯文本拓展至视觉层面,让语音识别突破 “只识文字” 的局限,实现 “能识场景” 的升级。它通过辅助理解单图和多图内容,帮助用户在搜拍或图片创作场景,精准识别易混淆字词,大幅提升识别准确性。
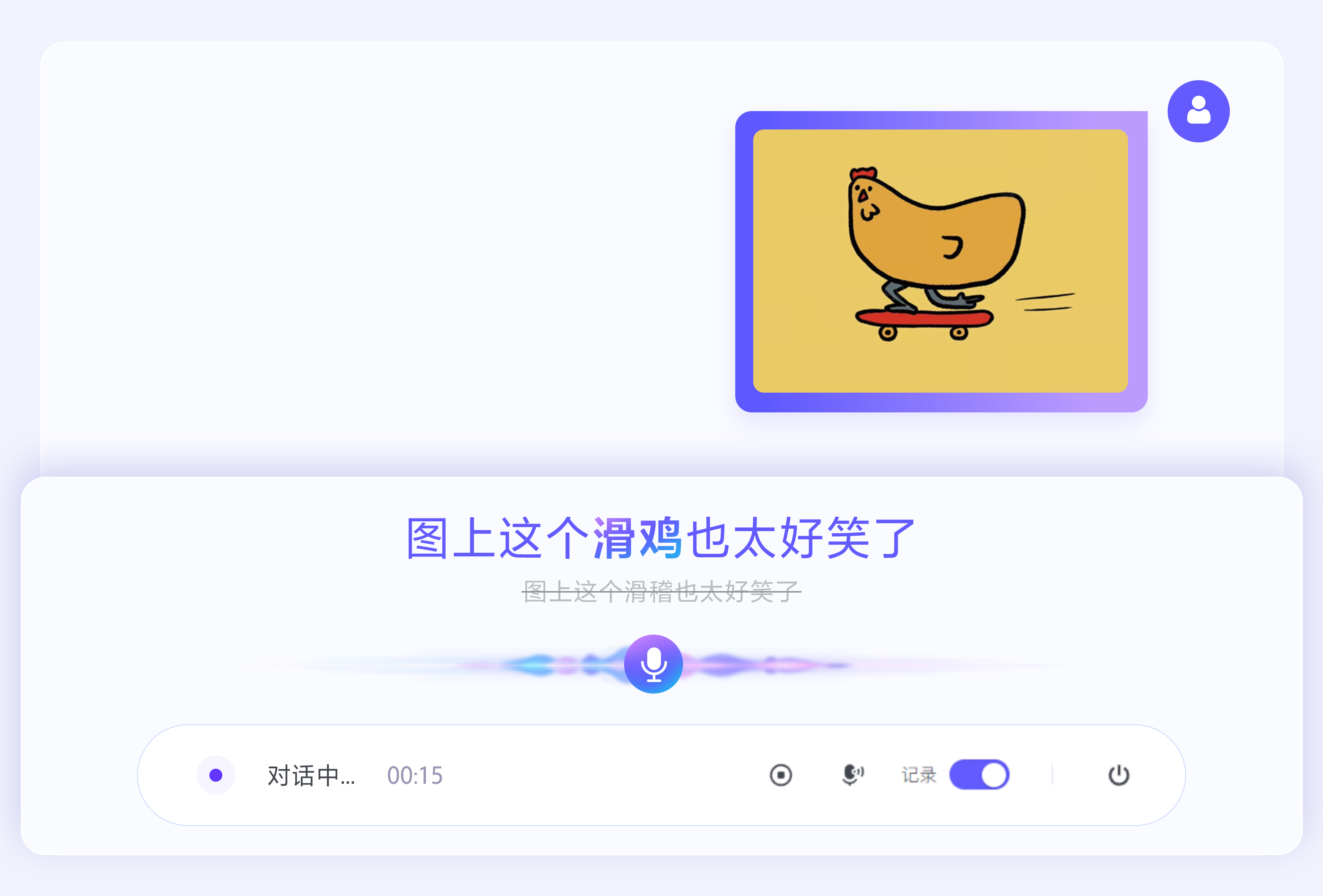
以搜拍场景为例,当用户发送照片后,若想描述画面内容,传统模型可能因 “滑鸡” 不常见而误识别为常用词 “滑稽”。而豆包语音识别模型 2.0 能同步解析图像,发现画面中是正在玩滑板的 “鸡”,从而精准判断用户想表达的是 “滑鸡”,避免字词混淆导致的识别偏差。
在图片创作场景中,越来越多用户选择用语音指令生成或修改内容,豆包语音识别模型 2.0 可智能结合当前图像内容进行辨析与纠错。当用户语音提及需修改的元素时,模型能精准判断其真实需求 —— 比如明确用户想调整的是画面中的 “马头”,而非同音且更常见的 “码头”,最终让图片生成贴合预期的画面。

13种语言精准识别:有效拓展跨语言应用场景
豆包语音识别模型 2.0 采用 Function Call 策略,在高度保持中、英和方言识别准确度的前提下,支持日语、韩语、德语、法语、印尼语、西班牙语、葡萄牙语等13类语种的精准识别。
目前,豆包语音识别模型 2.0 已正式上线火山方舟体验中心并对外提供API服务。未来,豆包语音识别模型 2.0 将持续进化,力求在多模态、多场景下实现更精准的语音识别,为企业提供更精准、高效的语音转文字服务。




